主要内容
使用msst在线服务
把msst部署到本地需要花费不少时间,对电脑有要求。为方便用户使用,我们把msst做出saas,服务部署到云端,推荐用户使用msst的在线服务,我们做了很多工作:
| 📶 测试了各种场景 | 各种音频视频格式及音乐风格 |
| 🧑🏻🤝🧑🏻 支持平台 | Windows |
| 🎼 测试哪些渠道 | 各短视频平台及常见的公开音乐源 |
| ⏱️ 时间 | 1 周 |
| 🎶 声音质量 | 高质量并清晰 |
| ✅ 处理速度 | 比uvr5更快 |
| 🏅 文件保存 | 文件保存云端,不容易丢失 |
你也许想知道:
分离模型介绍
推荐模型:伴奏分离模型melband_roformer_instvox_duality_v2.ckpt,这个模型的人声和背景音效果都不错,提取人声模型big_beta5e.ckpt,去除和声模型dereverb_echo_mbr_fused_0.5_v2_0.25_big_0.25_super.ckpt,分离和声模型model_mel_band_roformer_karaoke_aufr33_viperx_sdr_10.1956.ckpt,降噪模型denoise_mel_band_roformer_aufr33_sdr_27.9959.ckpt,修复声音模型Apollo_LQ_MP3_restoration.ckpt,分离嘈杂人声mel_band_roformer_crowd_aufr33_viperx_sdr_8.7144.ckpt,分离男女合唱bs_roformer_male_female_by_aufr33_sdr_7.2889.ckpt,提取吉他声提取贝斯声提取钢琴声提取鼓声模型HTDemucs4_6stems.th,去特效音model_bandit_plus_dnr_sdr_11.47.chpt
msst 是一款免费开源的音频分离项目,能够从基础音频中移除词干和其他对象,是目前最优秀的人声伴奏分离工具之一。国内用户访问:https://gitee.com/zhyqieqie/Music-Source-Separation-Training.git,github地址:https://github.com/ZFTurbo/Music-Source-Separation-Training.git
✅ 模型类别
- multi_stem_models:多音轨分离模型
- single_stem_models:单音轨分离模型,通常只提取两个stem,目标音轨和剩余音频
- vocal_models:针对于人声和伴奏分离的模型
第三方MSST模型分享
- Huggingface国外网站(需要魔法),打不开的可以把网站中的huggingface.co改成hf-mirror.com,其余部分不变,使用国内镜像站。
- 非官方MSST模型不做单独介绍,想了解这个模型可以做什么,可以通过模型名字了解或者下载下来使用。如果一个模型仓库中有多个模型,一般可以根据模型名字,以及模型上传时间,择优选取
- deton24的Google文档,里面包含了最新音频分离相关的消息。包括最新模型分享,最新UVR消息,最新改动等。想要第一时间获取最新消息的,可以关注此处的文档
MSST模型指标解释
- SDR(源失真比): SDR是衡量预测源(估计值)与参考源匹配程度的指标。它通过参考信号的能量与误差(参考信号与估计值之间的差异)的能量比来计算。返回的结果是以分贝(dB)为单位的 SDR 值。值越高表示性能越好。
- SI-SDR(尺度不变源失真比): SI-SDR 是 SDR 指标的一种变体,它对于估计值相对于参考信号的尺度变化是无关的(即忽略响度振幅变化)。其计算方法是先将估计值按比例调整以匹配参考信号,然后再计算 SDR。值越高表示性能越好。
- Bleedless & fullness: 参考信号和估计信号之间的“溢出”(bleed)和“饱满度”(fullness)度量。“溢出”指标衡量估计信号在多大程度上溢出到参考信号中,而“饱满度”指标则衡量估计信号在多大程度上保持其相对于参考信号的独特性。简单理解就是分离的完整性。这两个值越高表示完整性越好,说明分离特定乐器时,饱满程度越好。举个例子,例如分离人声伴奏,对于人声来说,溢出的越少(即bleedless指标越高),饱满度越高(即fullness指标越高),说明人声在伴奏中的残留越少,分离的越完整。
本地安装(webUI)
😊 安装条件
- 有英伟达显卡
- (不需要)魔法上网
- 磁盘空间>30G
✅ 官方链接:
- MSST原始下载地址:https://github.com/ZFTurbo/Music-Source-Separation-Training
- MSST webUI开源项目地址:https://github.com/SUC-DriverOld/MSST-WebUI
- MSST webUI开源项目文档:https://r1kc63iz15l.feishu.cn/wiki/JSp3wk7zuinvIXkIqSUcCXY1nKc
下载与安装:
- 用户可以下载发布(https://github.com/SUC-DriverOld/MSST-WebUI/releases/tag/1.7.0 )下载MSST软件。
- 安装过程中,用户需要配置FFmpeg和CUDA环境变量,以确保软件能够正常运行。
操作步骤:
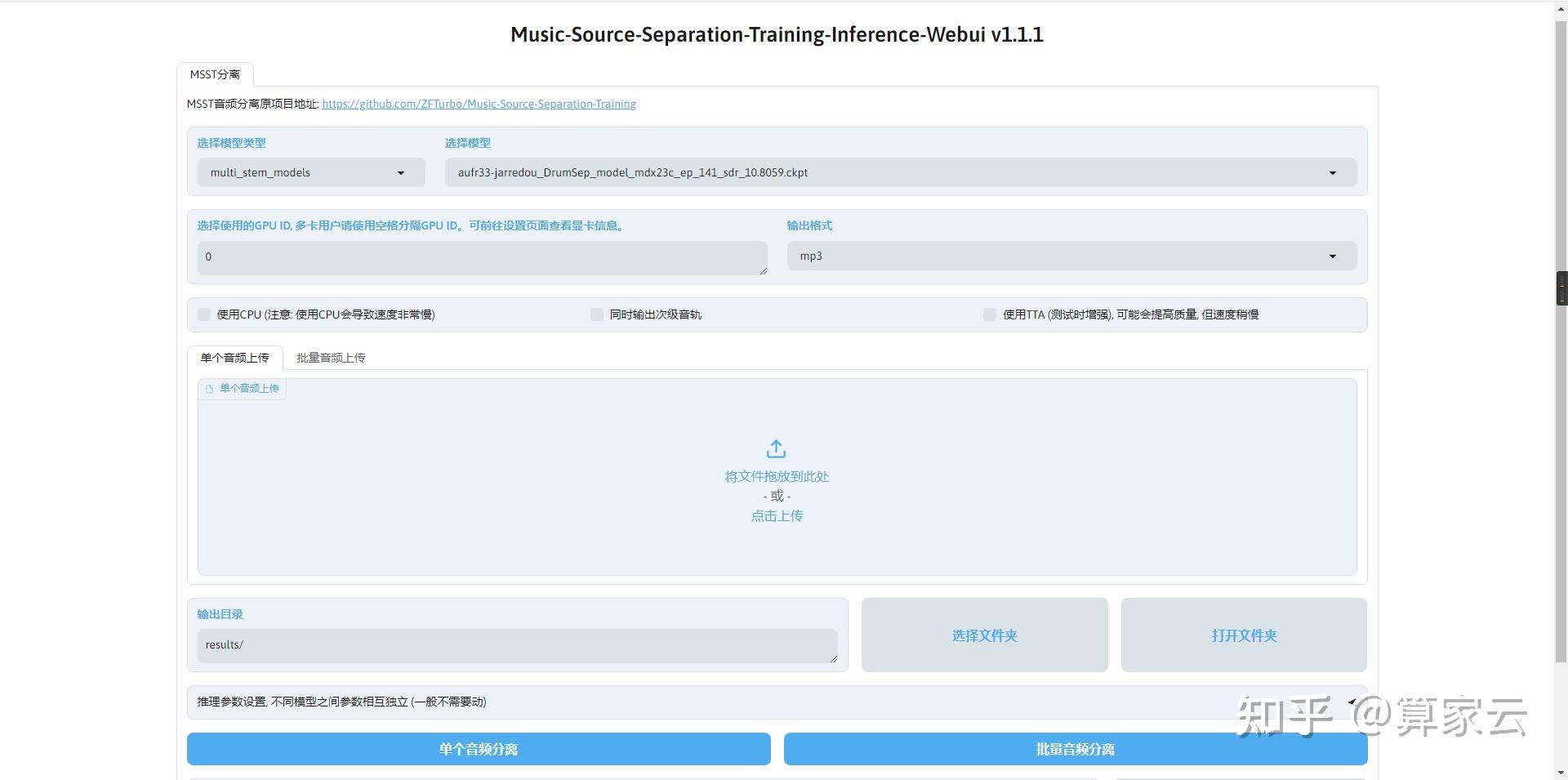
- 1、选择模型类型。
- 2、选择模型:根据需求选择你需要使用的模型。
- 3、输出格式:可以选择wav,flac,mp3格式输出。
- 4、选择输出音轨:不同的模型对应不同的输出音轨,按需勾选就行,支持多选。
- 5、- 使用CPU:MSST推理不建议使用CPU。据我测试,4分钟的音频,CPU(AMD Ryzen 7 6800H 12核)推理需要花费约30-40分钟。
- 6、- 输入音频:上传一个或多个需要分离的音频,可以点击上传也可以拖拽上传。
本地使用
😊 提取音乐的关键配置
- batch_size:一次要处理的批次数,越大占用越多显存。默认一般为1,如果仍然有空余显存,可以适当增大此值以加快速度。此值建议根据自己的电脑显存来调节到一个合适的值,如果专用显存吃满了,开始占用共享显存,会导致推理速度明显变慢。对于MSST来说,增大此值几乎不会影响推理速度。可以直接设置成1。
- num_overlap:窗口重叠长度,也可理解为每帧推理的次数。数值越小推理速度越快,但会牺牲效果。数值越大推理越慢但是效果更好。如果要平衡速度和质量,可以设置为4。如果嫌处理速度太慢,可以设置成2,牺牲部分质量(几乎听不出)来显著提升推理速度。此参数会影响推理速度和质量,但几乎不会影响显存占用。
- chunksize:音频切片大小,增大此值可以提高分离效果,但会增加处理时间和显存占用。每个模型的默认值都不一样。目前大部分的MSST模型支持的音频采样率都是44.1khz,而chunksize=采样率\times 切片秒数。
- 启用TTA:启用“测试时间增强”,勾选后处理时间乘以三,能“略微”提高质量(但是基本听不出来)。基本没必要勾选。
总结
本文汇总了 MSST 使用过程的一些关键信息。一些设置需要反复使用才能体会出来。
我们强烈建议非专业用户使用 深度音频的在线分离音频。
常见问题
在了解了上述高质量的人声去除器之后,这里还有一些其他相关的问题和答案供您学习
1. 我为何不继续使用UVR5?
你当然可以继续使用UVR5,但UVR5官方的稳定版已经停更将近一年(测试版一直在更新,也在逐渐支持新模型)。这个问题是非常不好回答的一个问题。就好比你问我烧饭应该用铁锅还是不锈钢锅。用什么不重要,关键是你烧的菜是什么,也就是指你用什么模型。软件只是一个壳子,真正起作用的,是加载的模型。不存在绝对的优劣差别!不用刻意去贬低,或者去吹捧某一款软件。
2. 使用MSST遇到问题应该找谁?
官方提供了详细的帮助文档https://r1kc63iz15l.feishu.cn/wiki/F7Q8wl8WUifskekzJdrcQpn4nje,也可以到github提问"
3. msst支持50系列显卡吗?
支持,看文档有详细说明https://r1kc63iz15l.feishu.cn/docx/X9fHdcLlToi74yx0lykcPB1Nncf?302from=wiki
